
Entry information : CgloCIIAA02_Naragc5
| Entry ID | 13169 |
|---|---|
| Creation | 2015-04-21 (Christophe Dunand) |
| Last sequence changes | 2015-04-21 (Christophe Dunand) |
| Sequence status | complete |
| Reviewer | Not yet reviewed |
| Last annotation changes | 2015-04-22 (Christophe Dunand) |
Peroxidase information: CgloCIIAA02_Naragc5
| Name | CgloCIIAA02_Naragc5 | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | Asco Class II type A [Orthogroup: CIIAA001] | ||||||||||||||||||||||||||||||||||||
| Taxonomy | Eukaryota Fungi Ascomycota Sordariomycetes Glomerellaceae Glomerella | ||||||||||||||||||||||||||||||||||||
| Organism | Colletotrichum gloeosporioides (Glomerella cingulata) [TaxId: 5457 ] | ||||||||||||||||||||||||||||||||||||
| Cellular localisation | N/D |
||||||||||||||||||||||||||||||||||||
| Tissue type | N/D |
||||||||||||||||||||||||||||||||||||
| Inducer | N/D |
||||||||||||||||||||||||||||||||||||
| Repressor | N/D |
||||||||||||||||||||||||||||||||||||
| Best BLASTp hits |
|
||||||||||||||||||||||||||||||||||||
| Gene structure Fichier |
Exons►
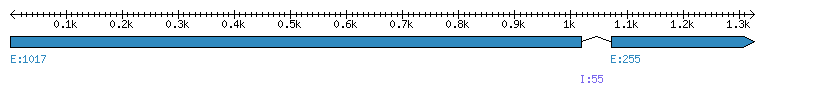
|
||||||||||||||||||||||||||||||||||||
Literature and cross-references CgloCIIAA02_Naragc5
| Literature | Gan,P.H.P., Ikeda,K., Irieda,H., Narusaka,M., O'Connell,R.J., Narusaka,Y., Takano,Y., Kubo,Y. and Shirasu,K. Genome analysis of Colletotrichum orbiculare and Colletotrichum gloeosporioides |
|---|---|
| DNA ref. | GenBank: NW_006762378.1 (357441..356115) |
| Cluster/Prediction ref. | Genebank: 18747594 |
Protein sequence: CgloCIIAA02_Naragc5
| Sequence Properties first value : protein second value (mature protein) |
|
||||||||||||
| Sequence Send to BLAST Send to Peroxiscan |
|
||||||||||||
| Remarks | Complete sequence from genomic (1 intron). | ||||||||||||
| DNA ► Send to BLAST |
|
||||||||||||
| CDS► Send to BLAST |
|
||||||||||||